While there are more polished and feature-rich LLM clients available, NextChat (PWA) has been sufficient for my daily needs. One thing I’d love to do is integrate it with my local Ollama server. This short guide will walk you through the process.
Prerequisites
- NextChat deployed as a PWA at some domain, e.g.
https://your-nextchat-pwa.com- If you deploy it to Cloudflare Pages, you can just use the
*.pages.devdomain
- If you deploy it to Cloudflare Pages, you can just use the
- Ollama with a local LLM model such as llama3.1 installed
Steps
Note: the commands shown below are for MacOS. For Linux, see Setting environment variables on Linux.
- Run this command in your terminal to allow additional web origins to access Ollama:
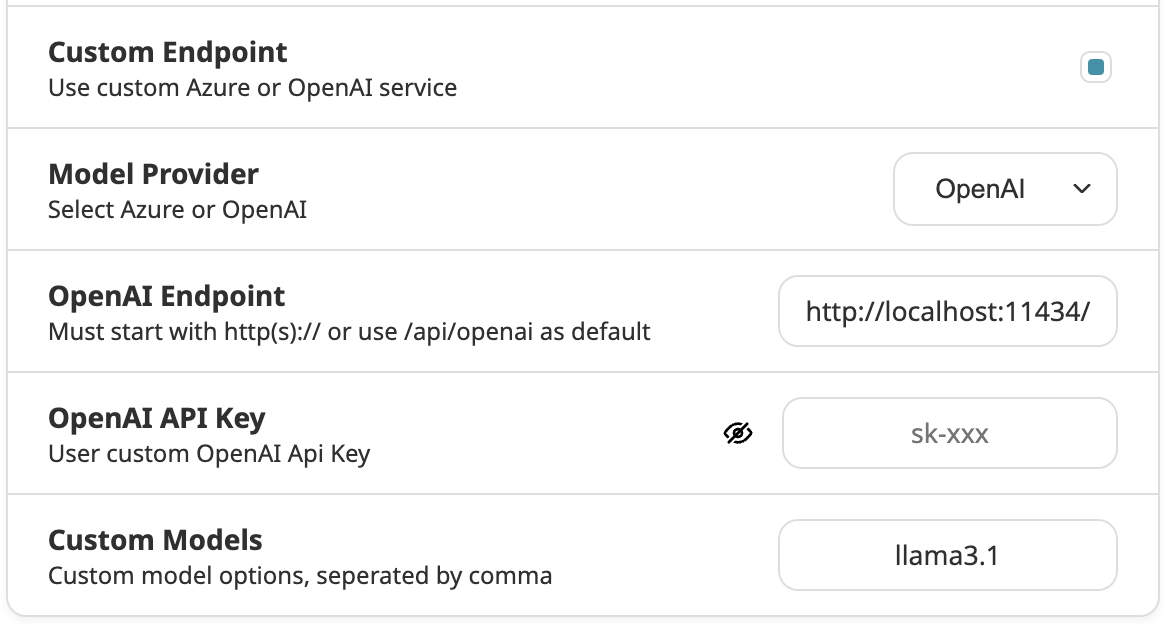
launchctl setenv OLLAMA_ORIGINS "https://your-nextchat-pwa.com" - Configure Ollama API in NextChat
- Leave OpenAI as the Model Provider
- Update OpenAI Endpoint to your local Ollama endpoint (the default endpoint is
http://localhost:11434/) - Leave OpenAI API Key empty
- Set Custom Model to the model you want to use, e.g. gemma, mistral, and llama3.1
- You can start using the local model. Don’t forget to set the model to
llama3.1 (llama3.1)in chats.
Tips
- By default, models are kept in memory for 5 minutes. You can increase that amount of time by setting the keep alive environment variable:
launchctl setenv OLLAMA_KEEP_ALIVE "30m"