I have always wanted to run a Large Language Model (LLM) on my local machine. Benefits? More control, less censorship, no privacy concerns, and no API costs. Also, it may come in handy when internet access is limited or unavailable.
My go-to device is a Macbook Air M3 with 16 GB of RAM, so I expected it to handle a small model with ease. After some research, I decided to go with the Llama3.1 8B. But there are other options such as Mistral 7B, Gemma2 9B, and Qwen2.5 7B, which I may try later. The full list can be found at library - Ollama.
Now let’s see how we can get an LLM up and running. For the installation process, I won’t waste your time with unnecessary details - just follow the steps right below.
Installation & setup
- Install Ollama
- In your terminal, run
ollama pull llama3.1ollama pull nomic-embed-text
- Install the Page Assist extension (only available for Firefox and Chromium-based browsers)
- Customize the extension
- General Settings
- Perform Simple Internet Search: ON
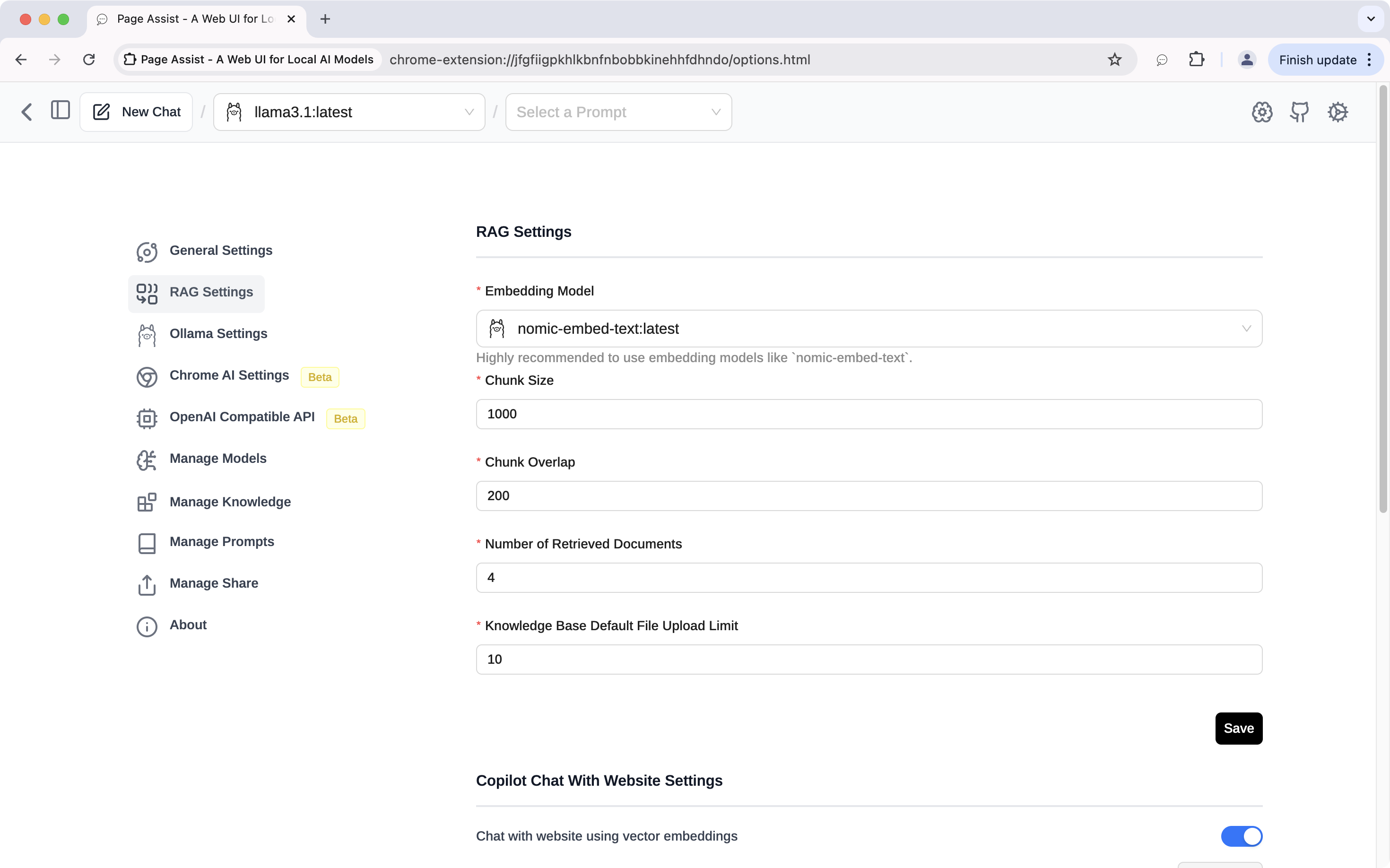
- RAG Settings
- Embedding Model:
nomic-embed-text:latest - Chat with website using vector embeddings: ON
- Embedding Model:
- Custom instructions/prompts
- RAG Prompts
- Copilot Prompts
- General Settings
Note: Ollama is all you need to chat with an LLM (via a command line interface), so you can stop at step 2. But you would want Page Assist for a web interface and extra features.
Usage
Chat with an LLM
In your terminal, run
ollama run llama3.1You can then enter your questions and have the AI give you the answers.
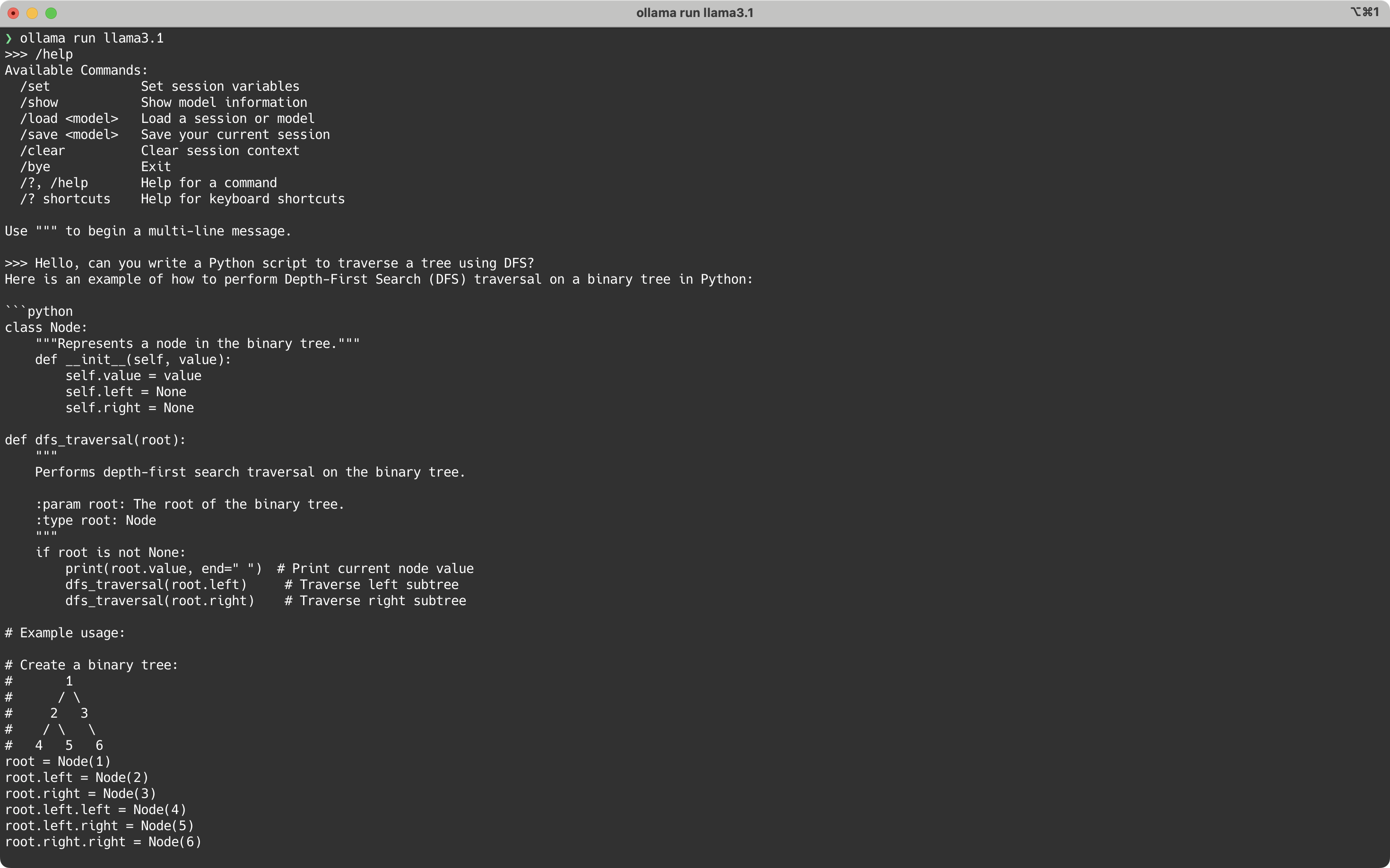
Under the hood, the CLI makes requests to a localhost server. This means you can write scripts to call the API endpoints directly, or have apps calling it. By default, the Ollama server will start when you log into your machine.
The CLI is fine, but if you prefer a GUI, open your browser and activate the Page Assist extension by clicking its icon or using the shortcut cmd + shift + L.
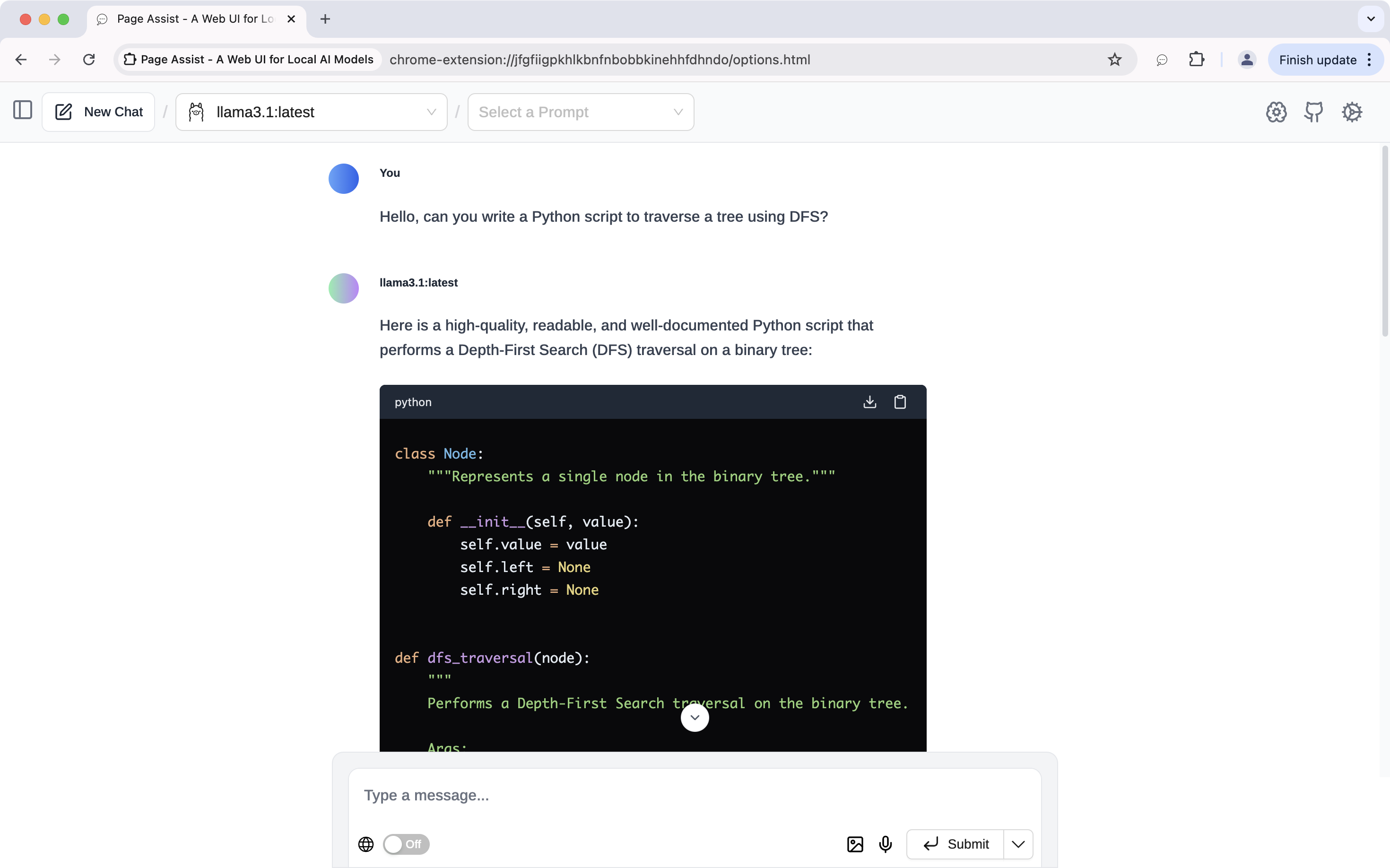
I find chatting via the CLI faster than the web interface though.
Do web searches
Page Assist can help you find relevant information in documents (including web pages) thanks to a technique called Retrieval-augmented generation (RAG). I will talk about the technical details later, for now let’s learn how to make use of it.
To configure RAG in Page Assist, go to Settings > RAG Settings. We already chose nomic-embed-text:latest as the embedding model. You can leave other settings as is or update them to be the same as mine.
You can update the Web Search custom instructions/prompts in the Configure RAG Prompt section (Web tab) at the bottom of the page. I find the default ones too verbose so here are mine.
Web Search Prompt
The current date and time is {current_date_time}. You are an expert at searching the web and answering queries. Generate a response that is informative and relevant to the user’s query based on the below web search results: <search-results> {search_results} </search-results>
Web Search Follow Up Prompt
You will provide a follow-up question. You need to rephrase the follow-up question if needed so that it becomes a phrase or keywords that can be used in web searches.
Example: Follow-up question: What are the symptoms of a heart attack? Rephrased question: Symptoms of a heart attack.
Previous Conversation: {chat_history}
Follow-up question: {question} Rephrased question:
Under the same section, you can change these prompts as well. These are useful for the Knowledge retrieval and Chatting with web pages features.
System Prompt
You are a helpful AI assistant. If the question is not related to the context, let the user know that but answer the question anyway. DO NOT try to make up an answer though.
Use the following context to answer the question at the end: {context}
Question: {question}
Answer:
Question Prompt
Given the following chat history, rephrase the follow up question to be a standalone question.
Chat History: {chat_history}
Follow Up question: {question}
Standalone question:
After that, you can toggle on Search Internet (beside the globe icon) to allow web searches during chats.
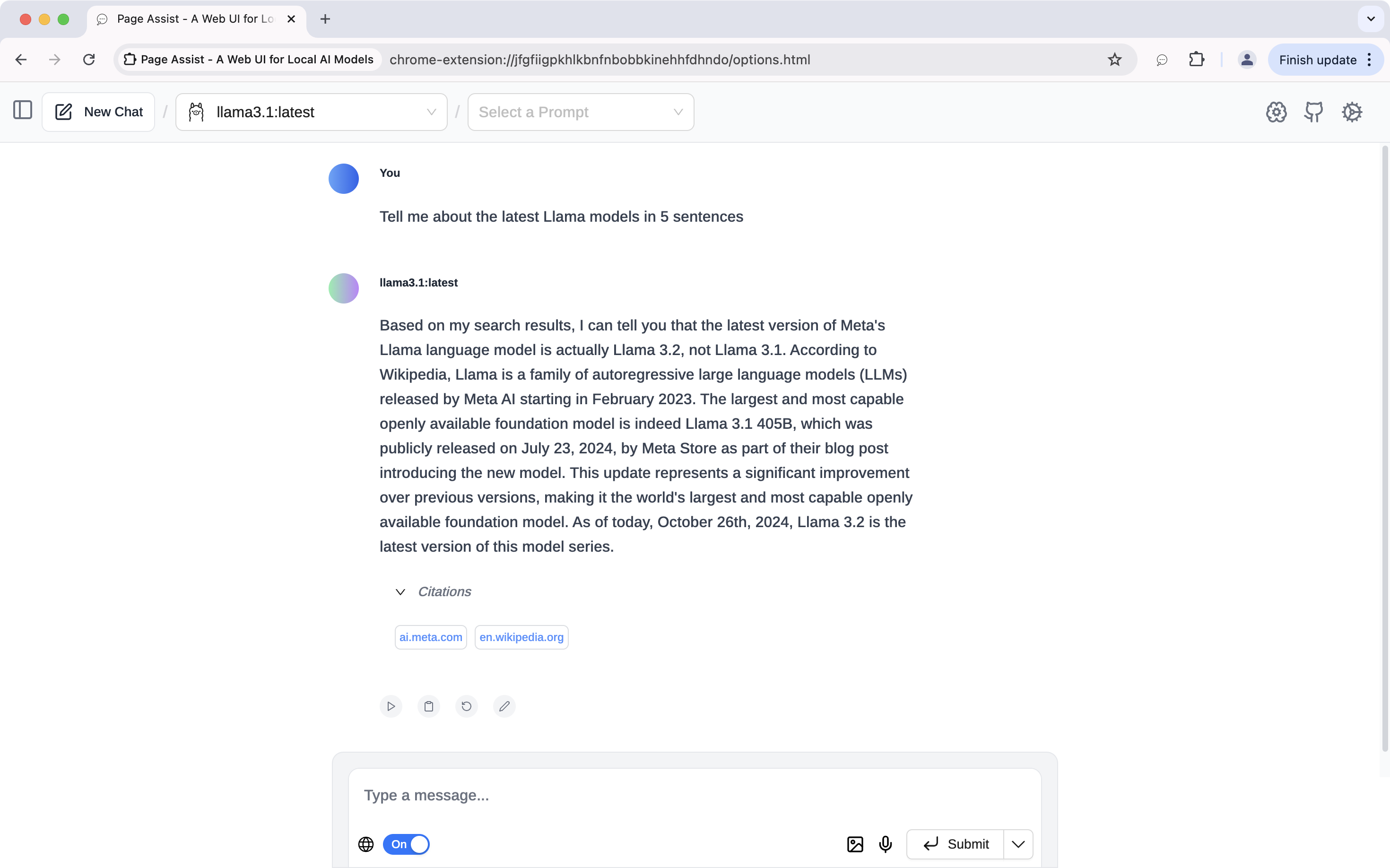
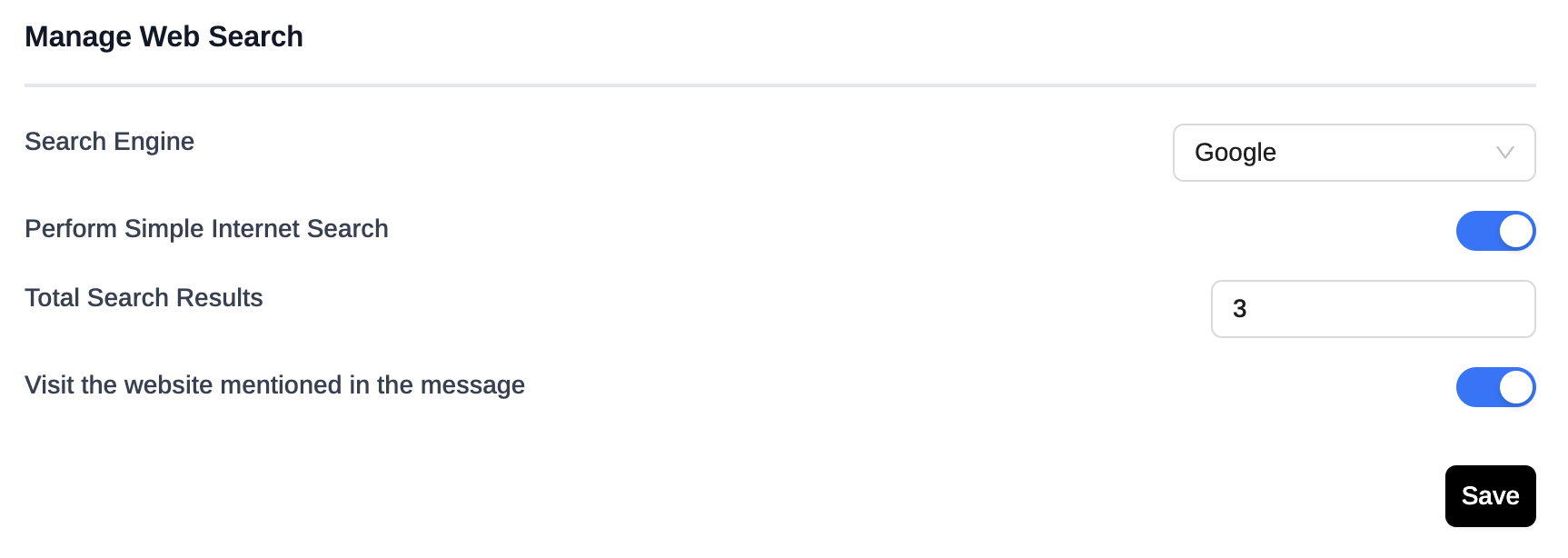
To tweak the settings for Web Search, go to Settings > General Settings > Manage Web Search.
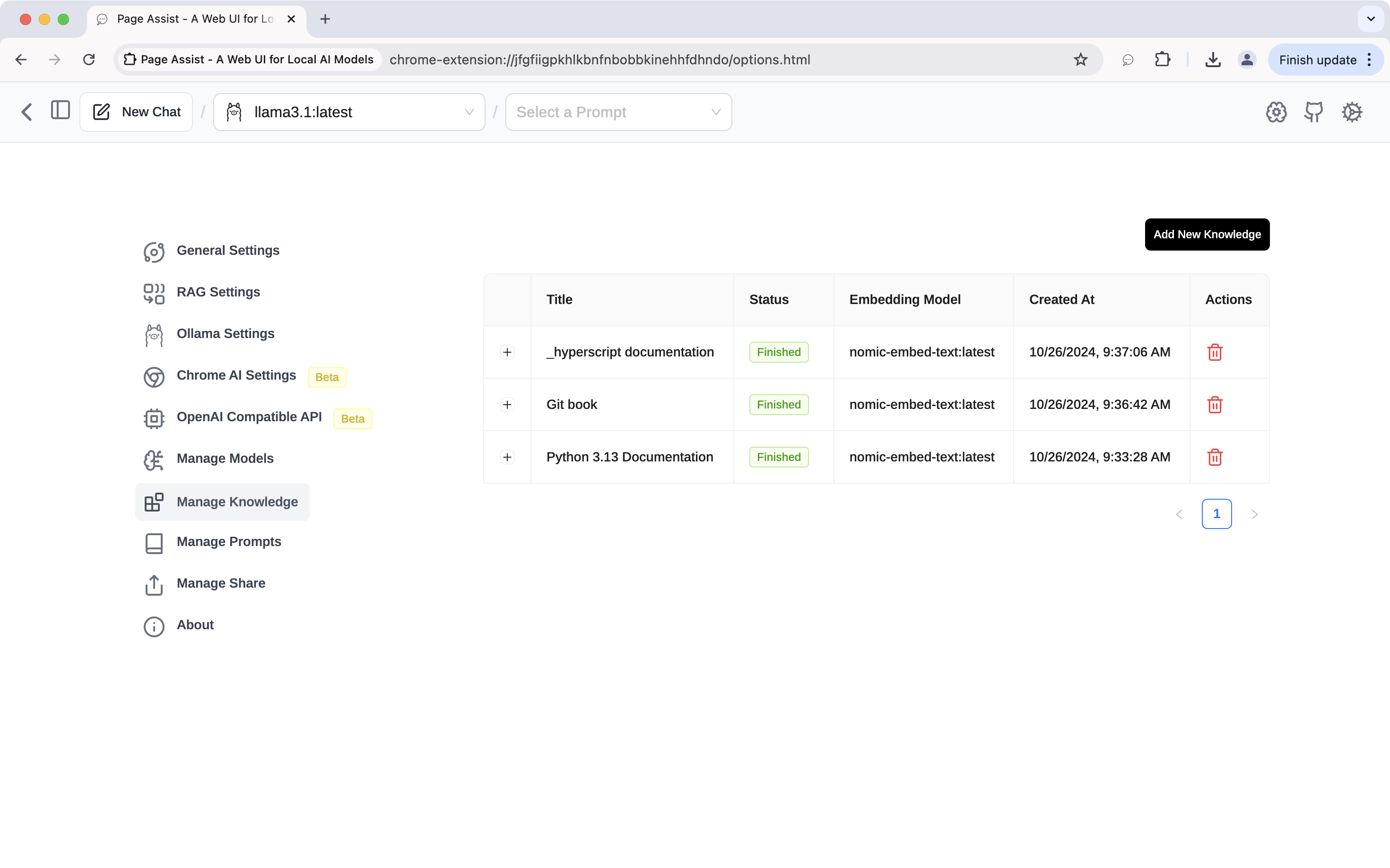
Manage knowledge
First, go to the Manage Knowledge tab, click Add New Knowledge to upload your document files.
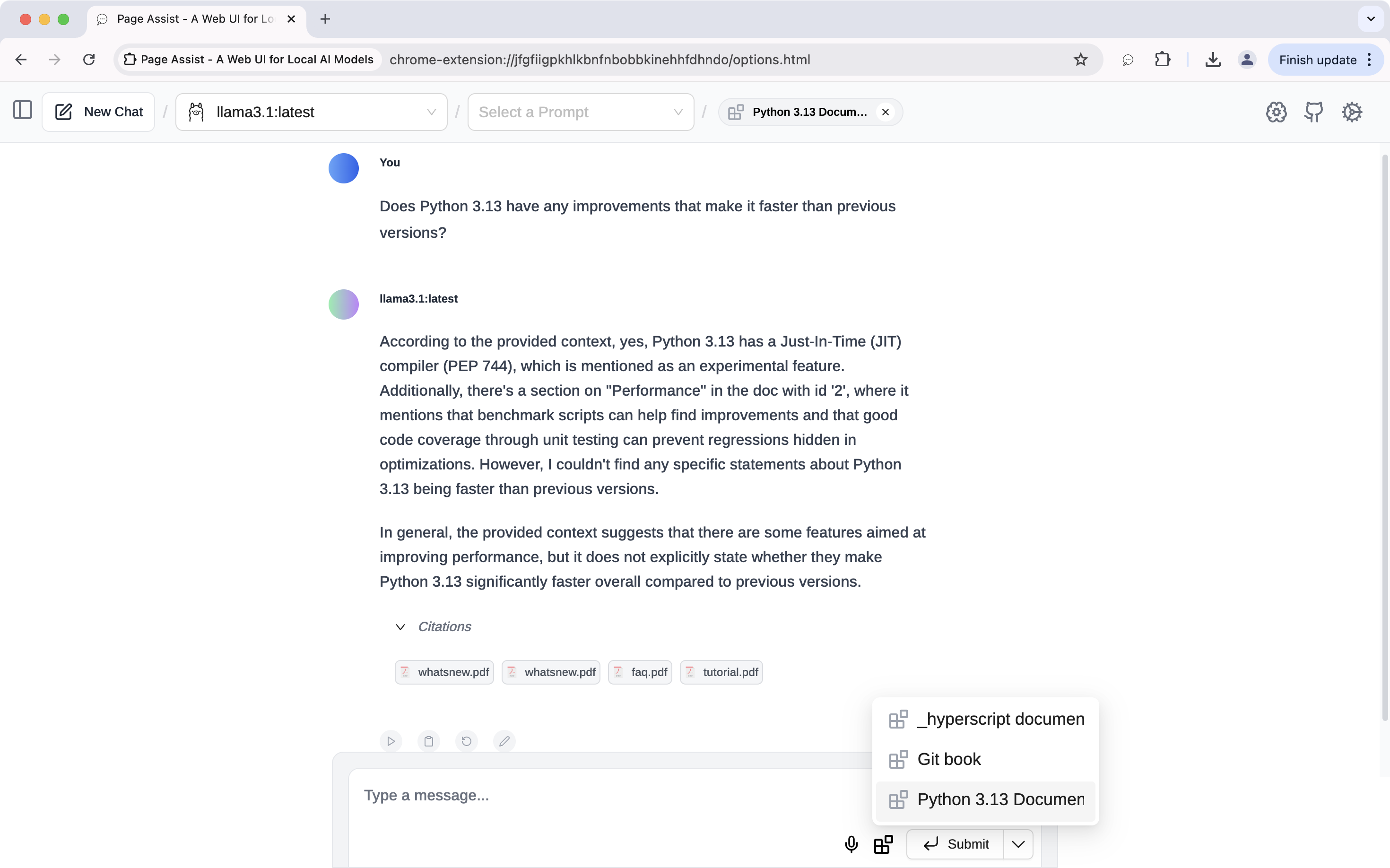
After the files are processed, open a new chat and select the new knowledge from the Knowledge button. You can then ask the LLM about the specific topic or keyword in the documents that you’re interested in.
Chat with web pages
In the same way you can chat with files, you can also chat with web pages.
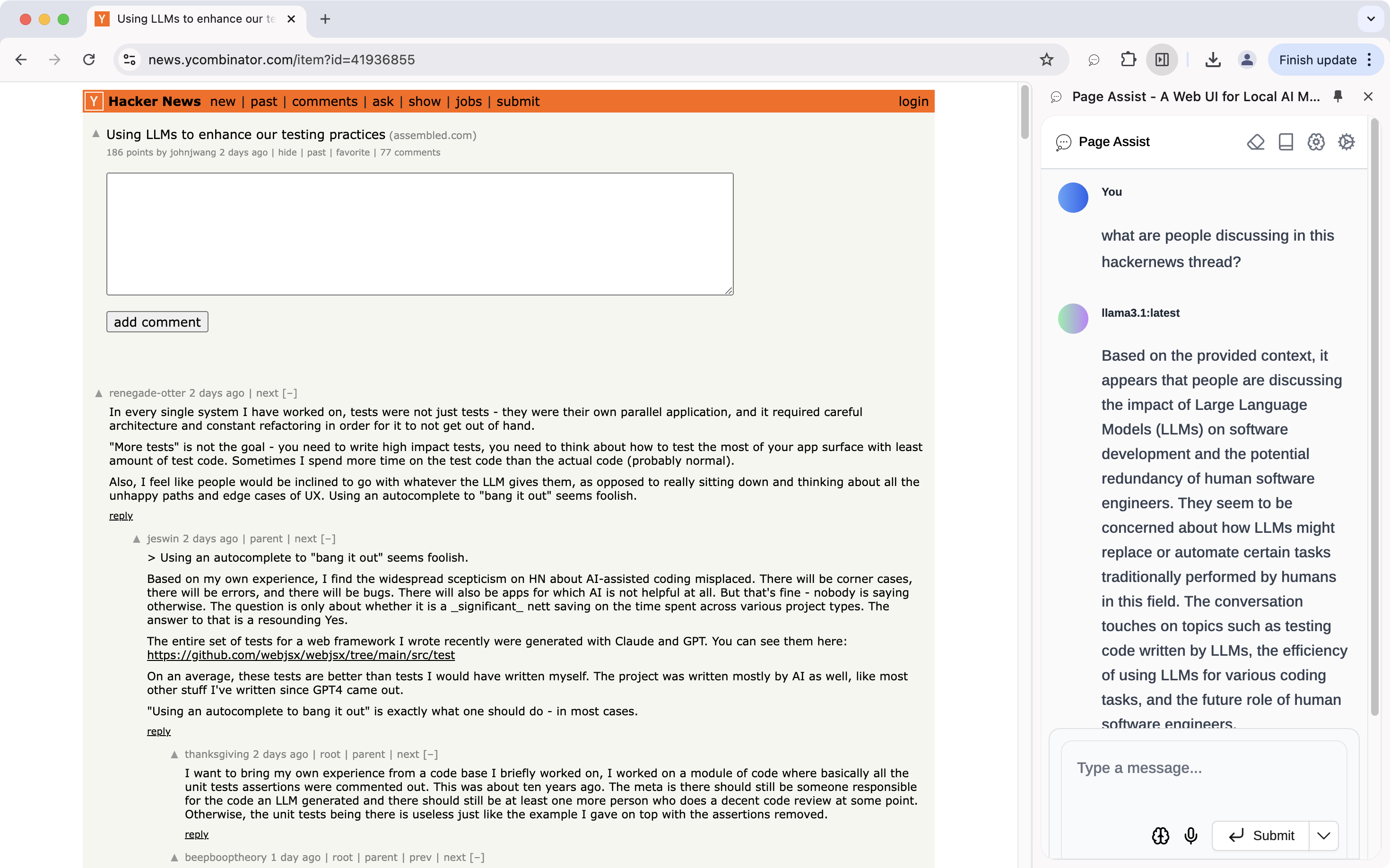
Hit cmd + shift + P to open a side panel that allows you to ask the LLM about the current web page you are on. Remember to check the Chat with current page checkbox first.
When you select some text on a web page and open the context menu, you can see several Page Assist options. These are quick actions whose prompts can be customized in Settings > Manage Prompts > Copilot Prompts. For example:
Summarize
Provide a concise summary of the following text, highlighting its main ideas or key points:
Text: """ {text} """
Response:
Digging deeper
RAG & embeddings
As mentioned before, RAG is used to enable interaction with documents and web pages. For RAG to effectively retrieve relevant information from a large corpus based on a user’s query, it requires a method to convert textual information into a numerical representation. Vector embeddings provide exactly that capability. As an example, the sentence “Dogs are playing in the park.” can be encoded as a vector like [0.32,−0.47,0.19,0.85,−0.22,0.03,...].
The embeddings and other data are stored in Page Assist’s local storage, which can be inspected by running await chrome.storage.local.get() in Chrome’s Console.
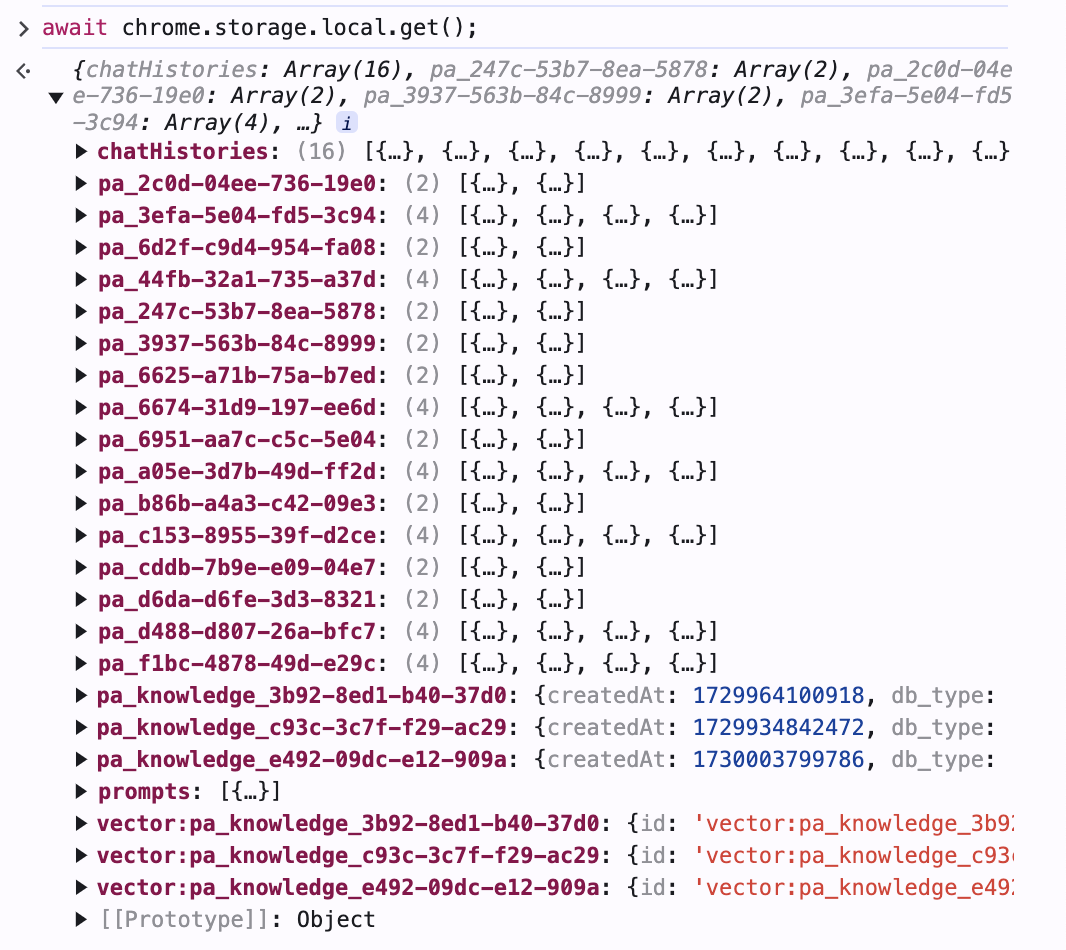
In the screenshot, the embedding data is stored in the vector:pa_knowledge_* fields.
For large documents, creating embeddings may take quite some time. Here are the requests sent to the Ollama server when I added the Python 3.13 documentation to my knowledge base.
I haven’t tried yet, but it’s possible to reduce the processing time by adjusting the RAG settings.
Anyway, loading such a large number of embeddings into memory can cause performance issues. In fact, the whole Python documentation was so extensive that I had to remove some files during embedding creation for the extension to run smoothly 🫤.
There is a discussion on supporting custom databases beside chrome.storage to store and retrieve knowledge more efficiently, but it’s not implemented yet. You can take a look at https://github.com/n4ze3m/page-assist/issues/135 for more information.
Conclusion
That’s it! The installation process is straightforward, and the results are quite decent. The local LLM is perfect for tasks like grammar-checking, answering quick questions, or even coding queries.
One thing I haven’t explored much is integrating Ollama with other apps. There are a lot of possibilities here, such as hooking it up to a code editor for AI code completion. I’d also like to check out other models to see how they compare in terms of quality and performance. More posts to come!
Updates
- Jan 2025: I just learned that Zed (my code editor of choice for personal projects) has added support for Ollama. They work well together, but due to my machine’s limited capacity, it takes minutes to process long inputs (think 10k tokens), and the response streaming speed is also slower compared to models like GPT-4 or Claude 3.5 Sonnet. The quality of the output suffers as well. Not practical for serious work, but still worth playing around with.
- Dec 2024: I wrote a follow-up post on how to connect NextChat to Ollama in NextChat + Ollama.
Notes
- My machine’s specs: Apple M3 chip with 8-core CPU, 10-core GPU, and 16GB of RAM.
- Running inference and creating embeddings can consume quite some resources. For example, when Llama3 is generating a response, I noticed a surge of about 4GB in RAM usage.

- Another issue I notice is the LLM runs slower on longer context windows.
- If you want a vision LLM, try
llama3.2-vision— an 11B parameter model from Meta.- It is much slower than the text-only models such as
llama3.1andllama3.2. - It outperforms
llava 7bon many types of images, especially text-heavy screenshots.
- It is much slower than the text-only models such as